Vor zwei Wochen ist mir wieder die automatische, monatliche Wartungsaufgabe von Homeassistant eingestellt worden. Ich prüfe dann immer die Logfiles nach Fehlern und installiere die anstehenden Updates.
Neben einigen Fehlern in den Protokollen (NSPanel) und einigen anstehenden Updates merkte ich schnell, dass die CPU-Last und Temperatur massiv zu hoch war.
Nur /config als Workspace öffnen
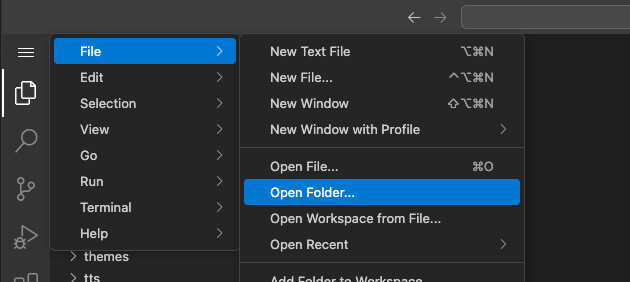
In Studio Code Server: File → Open Folder… → /config wählen.
(Wenn versehentlich / oder große Unterordner offen sind, scannt/indiziert VS Code das ganze Dateisystem.)
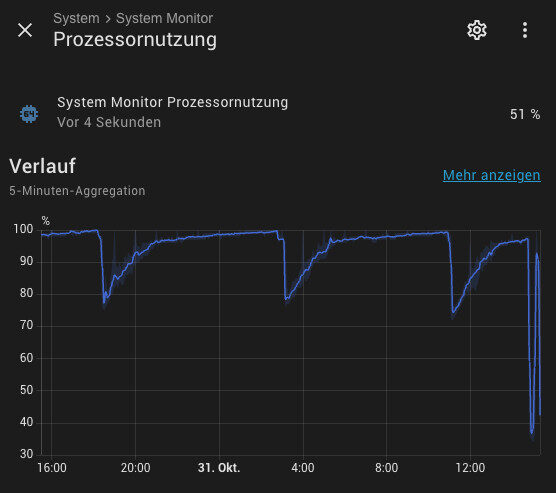
Also erstmal neu gestartet und den Verlauf der letzten Tage der Prozessornutzung angeschaut (siehe Bild).
Die Last ist immer mal wieder von 100% Richtung 80% eingebrochen. Ein Neustart brachte aber kurzfristig ein besseres Ergebnis: unter 40% aber ein schneller Anstieg auf wieder über 90%.
Meine Hoffnung, dass es sich um ein temporäres Problem handeln könnte, was durch einen Neustart behoben wird waren also dahin.
Also Ursachenforschung…
Angefangen habe ich damit, die ersten AddOns durchzuklicken, die ich unter Verdacht hatte großen CPU-Hunger zu haben, allen voran Frigate. Da war es aber relativ ruhig und so staunte ich nicht schlecht, als plötzlich beim AddOn Studio Code Server eine CPU-Nutzung von über 80% stand…
Das AddOn macht erstmal nichts aktiv, stellt mir eine Code-Editor zur Konfiguration zur Verfügung und verbraucht im Normalbetrieb etwa 1% CPU. Um es zu validieren: AddOn stoppen. Sofort geht die CPU-Last und Temperatur nach unten und nach erneutem Start sofort wieder auf Maximum.
Da ich viel mit Code und YAML arbeite habe ich schnell verworfen, das Plugin dauerhaft zu stoppen und nur bei Bedarf zu starten.
Ursache
Eine Recherche brachte — jetzt wo ich die Suche sehr genau eingrenzen konnte — verschiedene Vermutungen, die eine nach der anderen geprüft habe. Bereits die zweite Vermutung bestätigte sich: Workspace Indexing nach Neustart.
Ich hatte im Workspace nicht das Homeassistant Config-Verzeichnis (Standard) ausgewählt, sondern eine Ebene höher, weil ich vor ein paar Wochen eine Datei prüfen musste. Damit hat das AddOn versucht von da aus immer den gesamten Workspace zu indizieren.
Die vorgeschlagene Lösung (ins Config-Verzeichnis zu wechseln) brachte die Lösung.
Lösung
Studio Code Server öffnen > oben links die drei Menu-Striche auswählen > File > Open Folder… > /config auswählen > mit OK bestätigen
Das habe ich natürlich über mehrere Tage beobachtet und kann sagen, dass genau das die Lösung war, denn das AddOn braucht wieder um 1% — dauerhaft.
Automation für mehr Sicherheit
Die Idee ist, dass ich die CPU-Last und Temperatur überwache und bei Gefahr eine Wartungsaufgabe erstelle und eine Benachrichtigung an mein Mobilgerät schicke.
Helfer: CPU kritisch
Über meine template.yaml habe ich mir einen Helfer (binärer Sensor) angelegt, der eingeschaltet wird, wenn der CPU-Zustand kritisch (Prozessorlast über 55% oder Temperatur über 70°C) ist. Zudem führt der Helfer als Trribute die genauen, aktuellen Werte mit.
# ---------------------------------------
# CPU kritischer Zustand (Last/ Temperatur)
- binary_sensor:
- name: "CPU kritisch"
unique_id: cpu_kritisch
icon: mdi:cpu-64-bit
state: >
{{ states('sensor.system_monitor_prozessornutzung')|float(0) > 55
or states('sensor.system_monitor_prozessortemperatur')|float(0) > 70 }}
attributes:
cpu_load: "{{ states('sensor.system_monitor_prozessornutzung')|float(0) }}"
cpu_temp: "{{ states('sensor.system_monitor_prozessortemperatur')|float(0) }}"
Über einige Versuche habe ich festgestellt, dass ich drei Automationen benötige, um meinen Vorstellungen gerecht zu werden.
Ist der Alarm-Zustand einmal erreicht und fällt nicht wieder in einen normalen Zustand, bekomme ich nur genau eine Meldung. Ich wollte aber — wenn ich das Problem noch nicht gelöst habe — regelmäßig erinnert werden. Darum unterscheide ich zwei Alarmierungs-Automationen:
Automation: CPU-Alarm Erstmeldung
Wenn der Zustand im Helfer für mehr als 15 Minuten kritisch ist soll ein ToDo in meine Wartungsliste eingetragen werden und eine Benachrichtigung an mein iPhone gesendet werden.
alias: CPU-Alarm - Erstmeldung & To-do
description: ""
triggers:
- entity_id: binary_sensor.cpu_kritisch
to: "on"
for: "00:15:00"
trigger: state
conditions:
- condition: template
value_template: >
{% set items = state_attr('todo.wartungsarbeiten','items') or [] %} {{
(items | selectattr('summary','search','CPU-Last') | list | count) == 0 }}
actions:
- variables:
cpu_load: "{{ states('sensor.system_monitor_prozessornutzung')|float(0)|round(0) }}"
cpu_temp: >-
{{ states('sensor.system_monitor_prozessortemperatur')|float(0)|round(0)
}}
- data:
title: "Home Assistant: CPU-Alarm"
message: 🚨 CPU-Last {{ cpu_load }} % / Temp {{ cpu_temp }} °C seit > 15 Min.
data:
url: /todo?entity_id=todo.wartungsarbeiten
push:
interruption-level: time-sensitive
sound:
name: Alarm_Haptic.caf
critical: 1
volume: 0.5
action: notify.mobile_app_stm_iphone
- target:
entity_id: todo.wartungsarbeiten
data:
item: "🚨 Wartung: CPU-Last {{ cpu_load }} % / Temp {{ cpu_temp }} °C"
description: |-
Seit über 15 Min. Schwellwerte überschritten!
Ausgelöst: {{ now().strftime('%d.%m.%Y %H:%M') }}.
action: todo.add_item
mode: single
Der Trigger (Zeilen 3-7) prüft also, ob mein Helfer von oben für mehr als 15 Minuten im Status on ist.
In den Conditions (Zeilen 8–12) prüfe ich zudem, dass es noch keine Aufgabe mit „CPU-Last“ in meiner ToDo Liste gibt.
Nur wenn das so ist, werden die Aktionen ausgeführt. Zuerst werden Variablen mit den Werten für cpu_load und cpu_temp definiert (Zeilen 14–18), weil ich die später mehrfach benötige. Das macht es deutlich übersichtlicher.
Dann wird eine Benachrichtigung an mein iPhone (Zeilen 19–30) geschickt. Bei Tap auf die Benachrichtigung wird direkt in die ToDo Liste verlinkt (Zeile 23). Die Zeilen 26–29 führen dazu, dass der Sound Alarm_Haptic.caf abgespielt wird und das in 50% Gerätelautstärke als kritische Benachrichtigung, d.h. Ton-Alarm obwohl ich das Telefon auf Stumm geschaltet habe (habe ich meistens).
Zuletzt wird eine Aufgabe angelegt (Zeilen 31–39) mit mehr Details, insbesondere auch dem aktuellen Zeitpunkt.
Automation: CPU-Alarm Wiederholung
Wenn der Zustand im Helfer für mehr als 15 Minuten kritisch ist soll ein ToDo in meine Wartungsliste eingetragen werden und eine Benachrichtigung an mein iPhone gesendet werden.
alias: CPU-Alarm - Wiederholte Erinnerung 08-22 Uhr alle 2h
description: ""
triggers:
- hours: /2
minutes: "0"
seconds: "0"
trigger: time_pattern
conditions:
- condition: time
after: "08:00:00"
before: "22:00:59"
- condition: state
entity_id: binary_sensor.cpu_kritisch
state: "on"
for: "00:15:00"
actions:
- variables:
cpu_load: "{{ states('sensor.system_monitor_prozessornutzung')|float(0)|round(0) }}"
cpu_temp: >-
{{ states('sensor.system_monitor_prozessortemperatur')|float(0)|round(0)
}}
since: >
{{
as_local(states.binary_sensor.cpu_kritisch.last_changed).strftime('%d.%m.%Y
%H:%M') }}
dur: >
{% set sec = (as_timestamp(now()) -
as_timestamp(states.binary_sensor.cpu_kritisch.last_changed))|int %} {%
set h = (sec // 3600) %} {% set m = ((sec % 3600) // 60) %} {{
'%02d:%02d h'|format(h, m) }}
- data:
title: "Home Assistant: CPU-Alarm (Erinnerung)"
message: |-
🔁 CPU-Last {{ cpu_load }} % / Temp {{ cpu_temp }} °C weiterhin zu hoch.
Seit: {{ since }} (Dauer: {{ dur }}).
data:
url: /todo?entity_id=todo.wartungsarbeiten
push:
interruption-level: time-sensitive
action: notify.mobile_app_stm_iphone
mode: single
Der Trigger (Zeilen 3-7) und Conditions (Zeilen 8–15) stellen sicher, dass ich alle zwei Stunden alarmiert werden in der Zeit zwischen 08:00 und 22:00 Uhr und das nur, wenn der CPU-Sensor länger als 15 Minuten kritisch (also on) ist.
In den actions (Zeilen 17–30) werden wieder Variablen definiert. Wie zuvor cpu_load und cpu_temp. Da ich in den Erinnerungen aber auch den Zeitpunkt der Erstalarmierung (since) und die Dauer (dur) bekommen möchte, werde auch diese Informationen in Variablen abgelegt.
Mit den Informationen wird dann die (normale, also nicht kritische) Benachrichtigung in den Zeilen 31–40 zusammengebaut. Es wird keine Aufgabe erstellt.
Automation: CPU-Alarm Aufräumen bei Entwarnung
Sollte sich das Problem eventuell von selbst beheben oder ich vergessen die Wartungsaufgabe als erledigt zu markieren räumt die letzte Automation auf — ja so faul bin ich.
alias: CPU-Alarm - Aufräumen bei Entwarnung
description: ""
triggers:
- entity_id: binary_sensor.cpu_kritisch
to: "off"
for: "00:05:00"
trigger: state
actions:
- variables:
items: "{{ state_attr('todo.wartungsarbeiten','items') or [] }}"
ids: |
{{ items
| selectattr('summary','search','CPU-Last')
| map(attribute='uid') | list }}
- choose:
- conditions:
- condition: template
value_template: "{{ ids | count > 0 }}"
sequence:
- repeat:
for_each: "{{ ids }}"
sequence:
- target:
entity_id: todo.wartungsarbeiten
data:
uid: "{{ repeat.item }}"
action: todo.remove_item
mode: single
Der Trigger (Zeilen 3-7) prüft ob der Helfer (cpu_kritisch) seit länger als fünf Minuten aus (also Normalzustand) signalisiert.
Dann wird in den Zeilen 9–14 erst wieder für die benötigten Variablen gesorgt und schließlich (Zeilen 15–27) nach den entsprechenden Einträgen in meiner ToDo-Liste gesucht und die Einträge — wenn sie gefunden werden — entfernt.
Ich weiß, dass die Gefahr besteht, dass nur nach einem Text gesucht wird und somit anderen Aufgaben, die diesen Text enthalten, aus Versehen gelöscht werden könnten. Das nehme ich der Einfachheit aber hin und schätze das Risiko als sehr gering ein.
